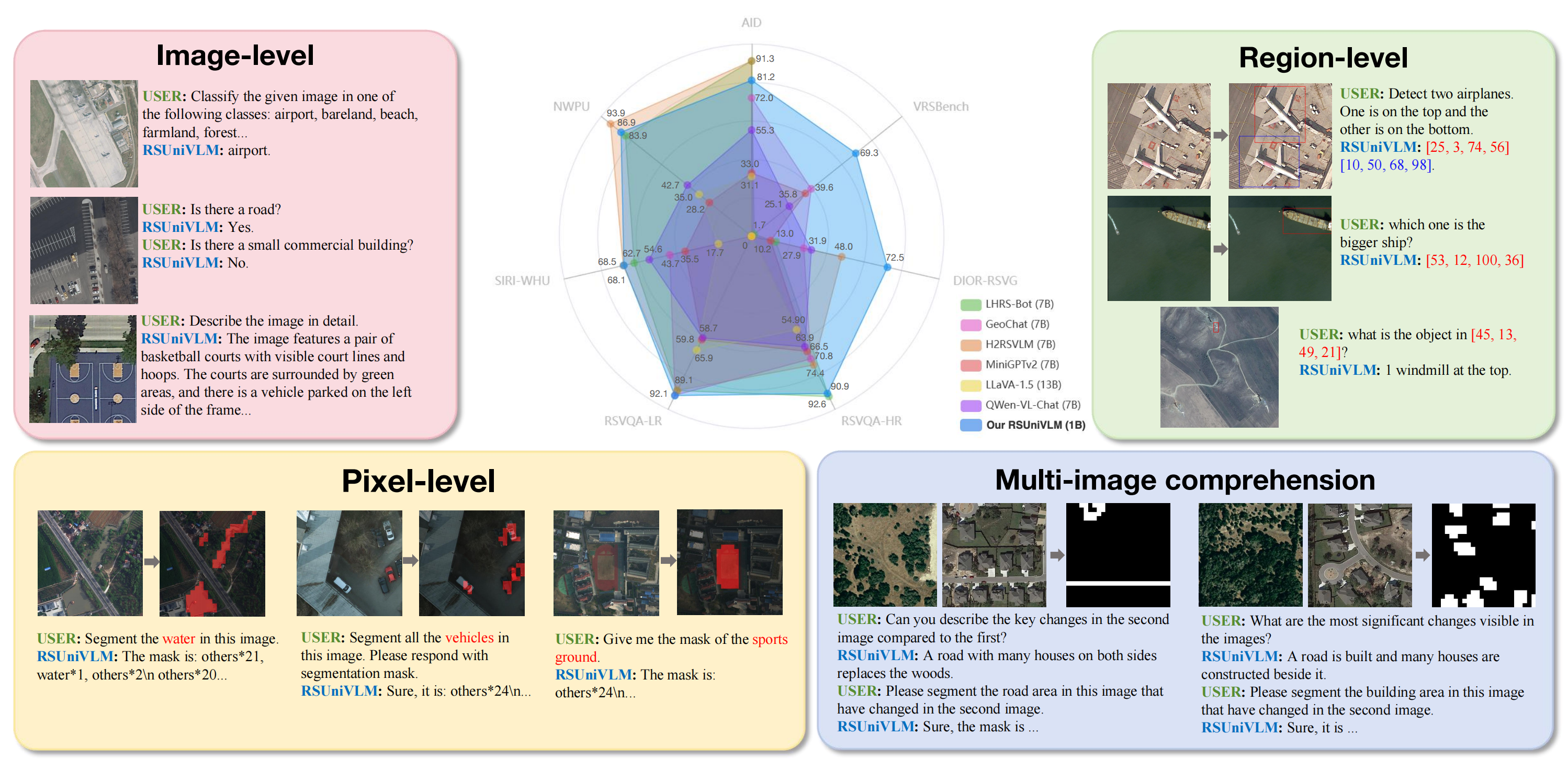
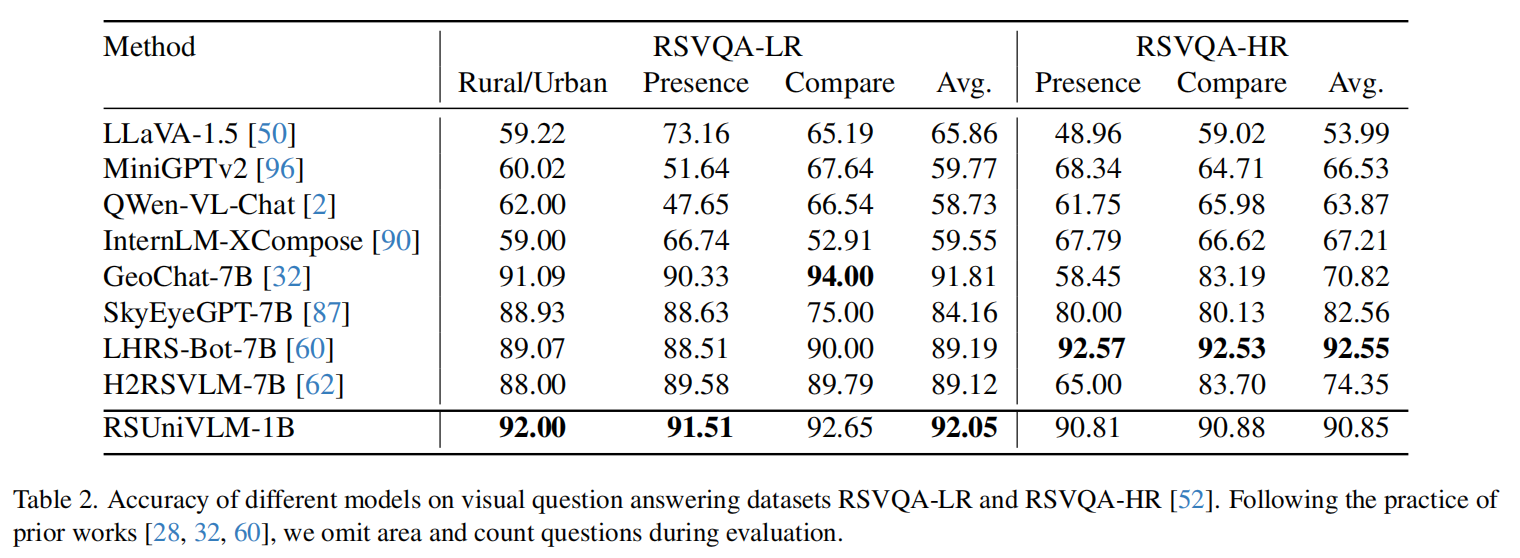
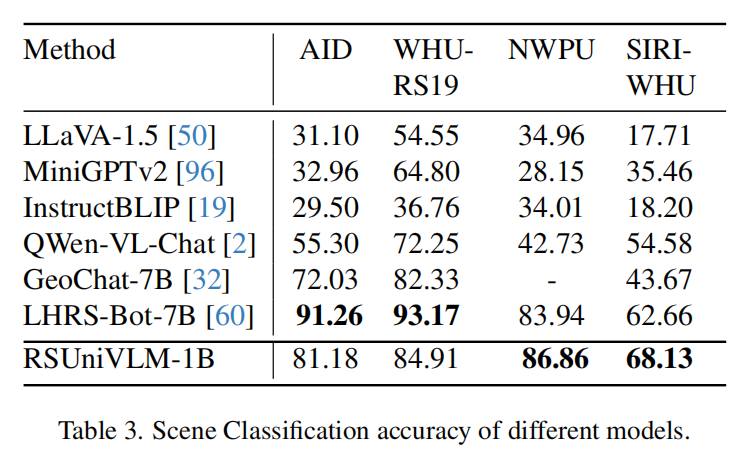
We propose RSUniVLM, a unified, end-to-end RS VLM designed for comprehensive vision understanding across multiple granularity, including image-level, region-level, and pixel-level tasks. RSUniVLM also performs effectively in multi-image analysis, with instances of change detection and change captioning. To enhance the model’s ability to capture visual information at different levels without increasing model size, we design a novel architecture called Granularity-oriented Mixture of Experts to constraint the model to about 1 billion parameters. We also construct a large-scale RS instruction-following dataset based on a variety of existing datasets in both RS and general domain, encompassing various tasks such as object localization, visual question answering, and semantic segmentation. Substantial experiments have been conducted to validate the superiority of the proposed RSUniVLM up to state-of-the-art across various RS tasks.
Following the design paradigm of commonly used LLaVA-style frameworks, the proposed RSUniVLM consists of the following four key components: (1) an image encoder pretrained on extensive image-text datasets; (2) a word embedding layer for text embedding extraction; (3) a multi-layer projector (MLP) that facilitates alignment between image tokens and text embedding; and (4) a large language model (LLM) that jointly processes the aligned image and text embedding to generate textual outputs in an auto-regressive manner. For the input with multiple images, we use a weight-shared image encoder to extract features from each image separately, then we concatenate them along the embedding dimension directly.
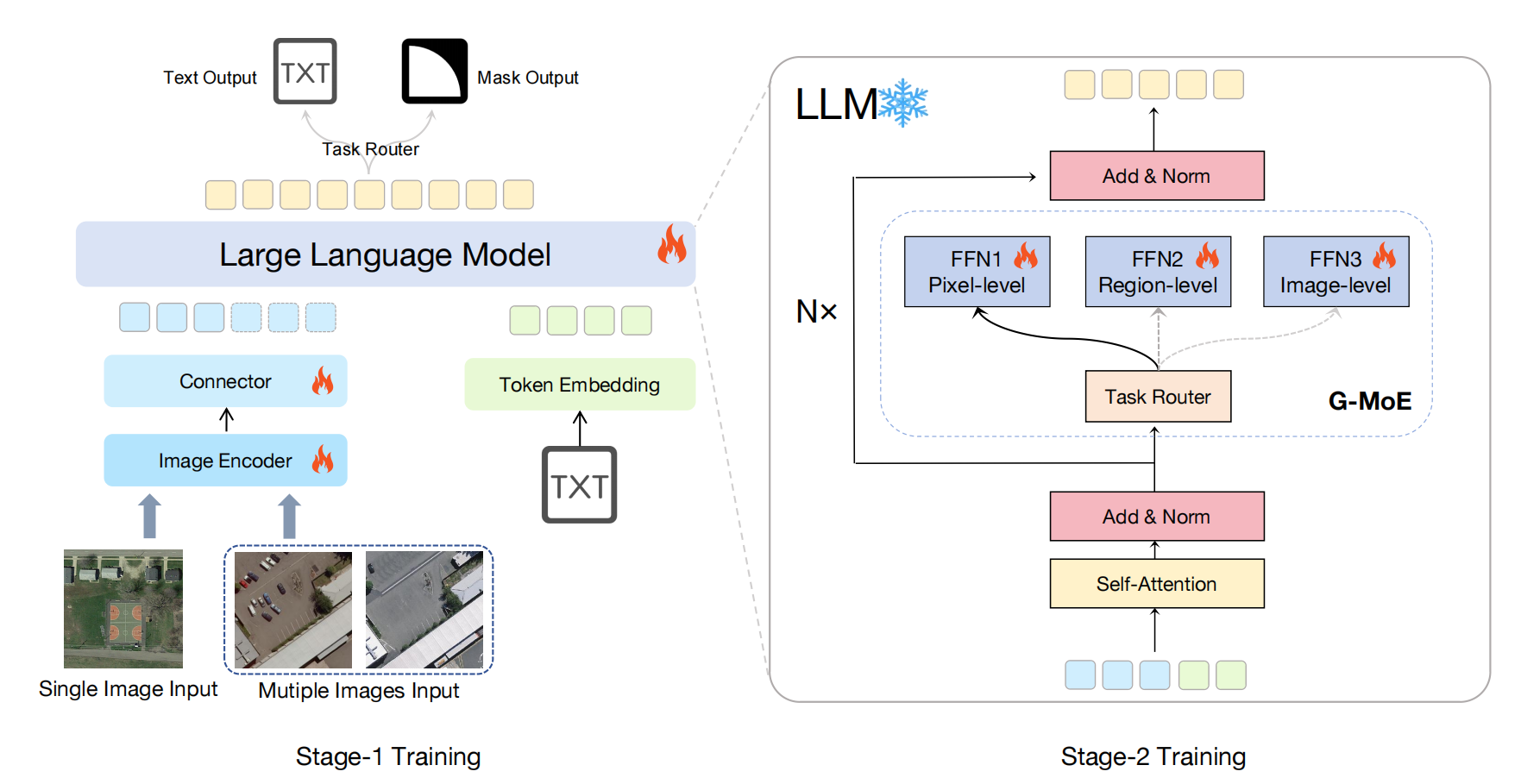
An overview of RSUniVLM. We adopt the classic LLaVA-based architecture, which consists of an image encoder, an MLP connector and a large language model. We unify all tasks into text-only generation, enabling joint optimization for multiple tasks in an end-to-end manner. During stage-2 training, Granularity-oriented MoE is applied to the LLM to enhance model's multi-level vision understanding.



@article{liu2024rsunivlm,
title={RSUniVLM: A Unified Vision Language Model for Remote Sensing via Granularity-oriented Mixture of Experts},
author={Xu Liu and Zhouhui Lian},
year={2024},
eprint={2412.05679}
}